December 3, 2020
File Reader
Architecture AI Project
Another File Reader: Revit Model Data
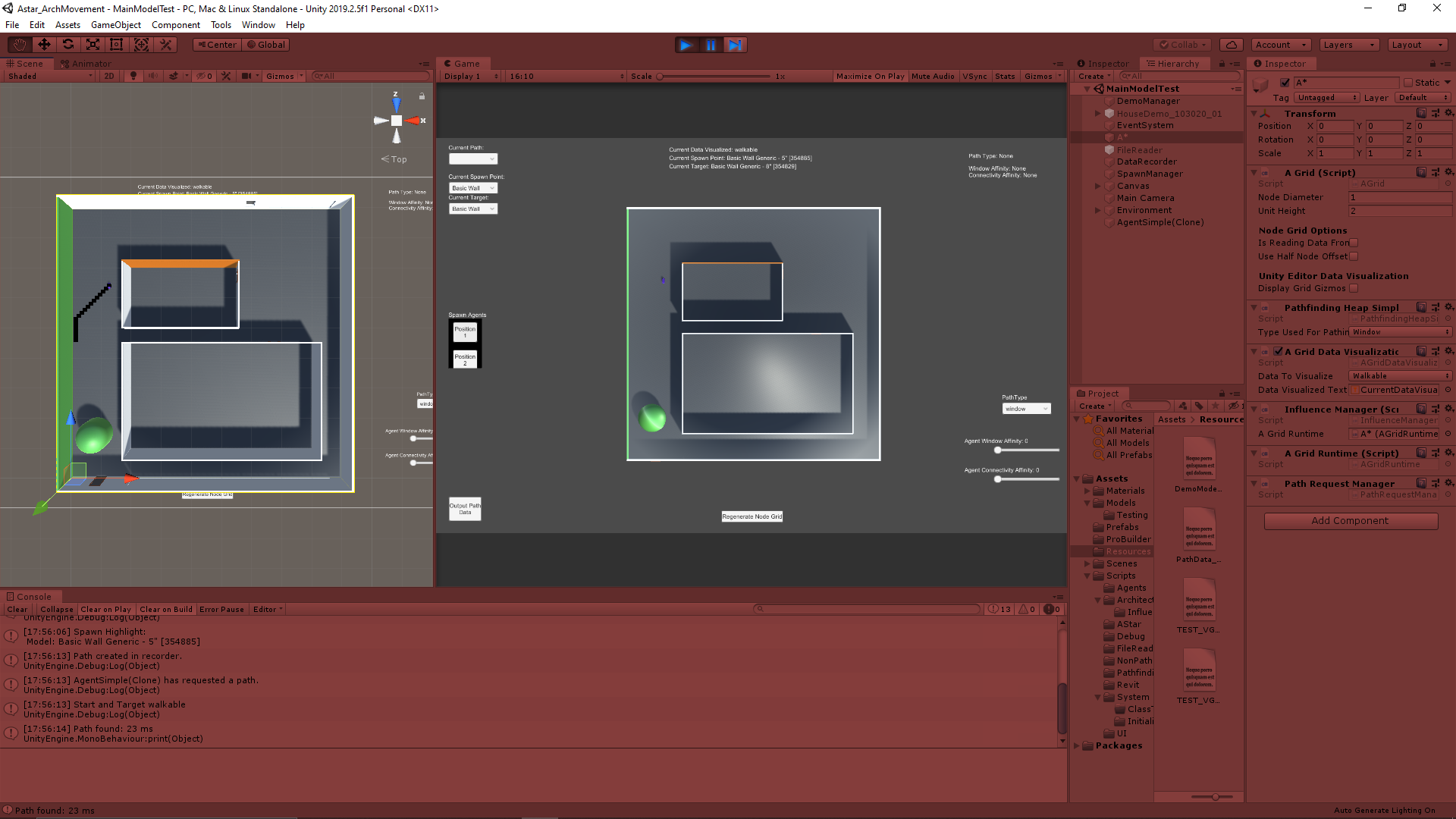
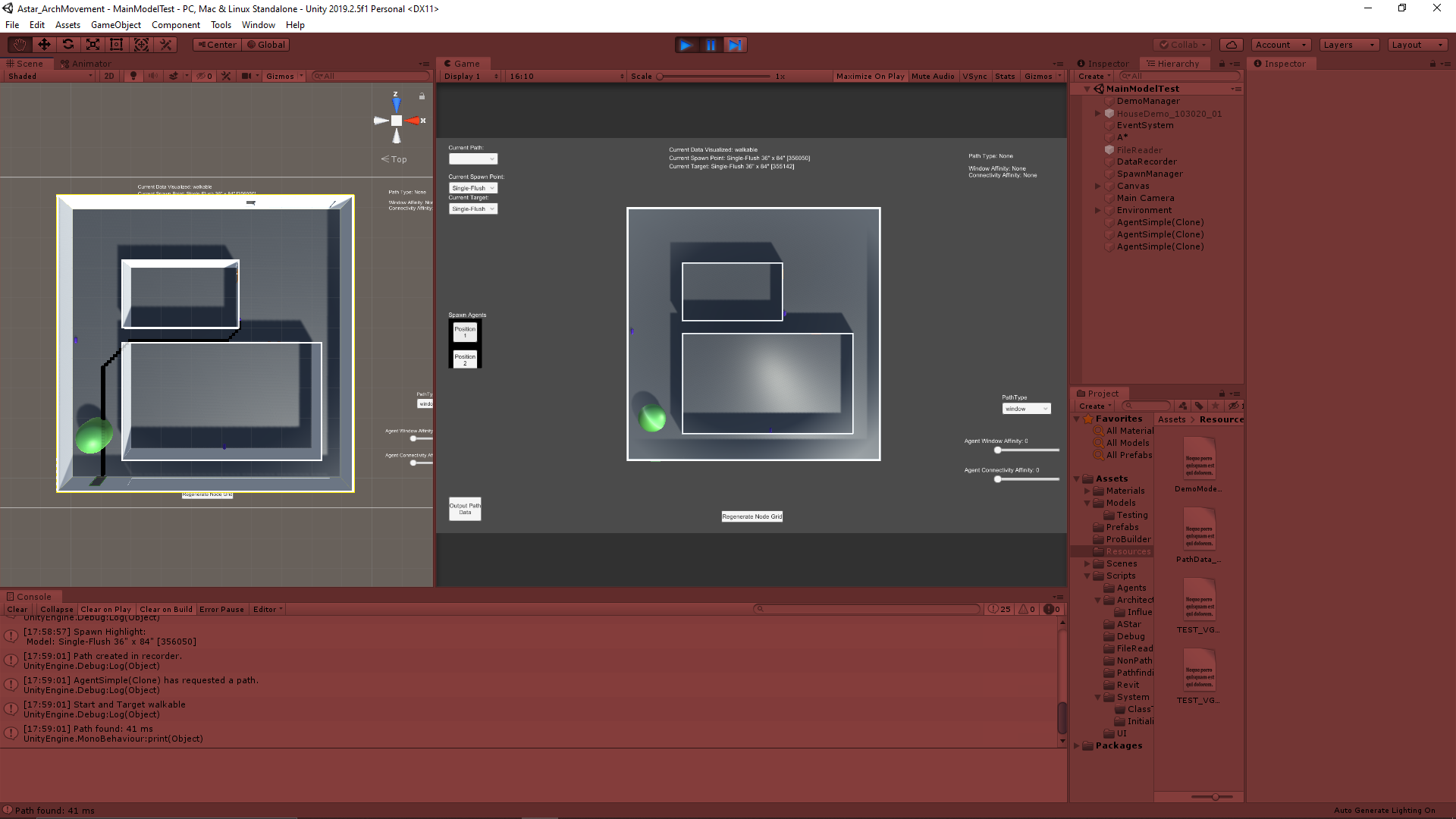
After reconstructing the file reader to read in various coordinate data to be passed on to the A* pathing node grid, we also needed a file reader to read in data from the Revit model itself to reapply that data to the models in Unity. Revit allows the user to apply many parameters and lots of data to the models contained within it, and that data can be exported as a large Excel file. That data however is not being passed into Unity when exported as an .fbx file, so we needed a way to reapply that data using the exported data.
Goal
While this is a flexible enough concept to apply many parameters, the main problem this system is being created to solve was automating the process of labeling what parts of the model are “walkable” or “unwalkable”. I had created a system to somewhat help do that in Unity, but this system will allow the user to do that work on the Revit side. They can create a “Walkable” parameter in Revit for specific objects and that information will be passed through Unity back onto the same object in the Unity model. A similar logic is being applied to which doors are passable in the overall model, with a parameter like “isClosed”.
Using the Revit Model Data
As of now, all the exported data is coming out in a large Excel .xlsx file which has dozens and dozens of sheets. These are difficult to innately read directly into Unity, so I investigated mass converting them into .csv files to be consistent with how we are already reading in the other types of data. I was able to find a VBA macro for Excel that simply exports all the sheets in a single Excel file as separate .csv files. I found the macro here:
Excel to Unity Pipeline
Once everything is converted into separate .csv files, they can all be moved to the Unity Resources folder to be easily read in and converted to data that can be used by the Unity system. Ideally this setup would be a bit more automated, but it works for now. Also, in most cases we only need a few of the dozens of .csv files created, so you can also just move the ones you actually need into the folder to keep everything cleaner.
Reading in the Revit Model .csv
Similarly to reading in the data for the pathing grid, I started by reading the data into an array that could then be easily accessed and passed through the Unity C# classes as needed. Again to keep it consistent and easier to read, I put the data into 2D arrays matching their layouts in the Excel file.
The initial part of this setup was actually so similar to how the other file reader was operating, I decided to move this functionality out into its own base FileReader class that had a static instance every class could access. Then the new file reader focusing solely on preparing the data for the Revit model application was its own class, and the original file reader class for reading data for the pathing grid was its own class.
Determining Which Data to Read In
Since there can be many sheets, leading to many .csv files, but we only need to access a very small subset of these sheets, I added a system to target which sheets of interest to look for. To keep the system flexible for now, it has a manual input system, but it can be automated if we are consistently looking for the same sheets.
I created a small data class that holds a string for the sheet of interest name and a string array for the name of the parameters (column headers) we are interested in within that sheet. These are serializable objects, and I created an array of them in the main file reader component that is accessible in the Unity Inspector. This lets the user select how many sheets they are interested in, then they type in the exact sheet name of each sheet and further add the name of the parameter(s) they are interested in. This is what determines which .csv files as well as which parts of the data to use when actually translated into data for the Unity system to use, .
Preparing the Data for Use in Unity
Identifying Objects in Model to Apply Data
I already had a system in place to find and apply modifications to objects in the model based on name, so I wanted to look to using that as a base for finding the objects here to apply the data to. Originally we were going to try and match the entire name of the object in the Unity model to the name in the Revit data, but this would take an extra step of crafting the name from the Revit data. This is because the object names are actually an amalgamation of several parameters for each object.
One of these parameters that is part of the name however, is an Id number. It appears these are unique for each object, and “Id” is one of the parameter columns in the Revit data. With this information, we can use the Id column to determine which objects we have data for and then finding the object in the model using a String.Contains method. The numbers should be unique enough this should not cause an issue in any realistic case.
Work In Progress: Applying the Data to the Models
After identifying the model objects that will be modified in the entire model and preparing the data to apply to them, the data just needs to be applied. Going back to the original goal, this currently always means interpreting the data to determine whether an object should be on the “Walkable layer” in Unity.
This however has the potential to be used in any case where Revit parameter data needs to do something to the model on the Unity side. As such, it makes sense to make an intermediate step which allows for many different functionalities if the need arises for a new way to apply the data to the objects in Unity.
Next Step
The first step is simply finishing this system, since I still have some work to do on the “Applying Data” step. Having the entire system in place with this much flexibility will then allow us to determine consistent use cases where we can automate the system to take care of those without user input (such as always checking the “Walls” .csv file to find if any walls are impassable and always checking the “Doors” .csv file to see which are open or closed). Then the next large step is reworking the raycasting system for informing the pathing node grid more accurately and consistently.
via Blogger http://stevelilleyschool.blogspot.com/2020/12/architecture-ai-pathing-project-another.html